Data-driven operations
| Objectives
Consolidate data capture to improve integrity and security.
Reduce the engineering level of effort to make data available for analytics, marketing, operations, and product feature use cases.
| Team Leads
Product: Brad Sherman
Engineering: Daynesh Mangal
| Insights
Engineers were the most sophisticated users of data. They required low latency, unstructured data for monitoring, alarming, and analysis. Some teams also required data to power product features, like recommendations and A/B testing.
The analytics team had requirements for regular reporting to commercial stakeholders, which needed to be created by analysts using GUI-based tools. The data scientists required access to lightly structured data to develop more sophisticated dashboards and ad hoc analyses for commercial stakeholders.
Product managers required structured consumer behavior and operational data to run ad hoc queries to gain insights into the performance of features.
Ad sales and marketing users required first-party data enriched with third-party data to create demographic and behavioral segments to target campaigns at specific consumers using GUI-based tools.
Data requirements had been historically met by integrating over 20 vendor SDKs into client applications with a growing backlog of additional SDKs.
SDK’s were not available for all device platforms, creating data gaps.
There was no methodology to monitor and alarm data captured by SDKs.
On average, an SDK took 6 resource weeks per device platform to develop, test and release.
The product line consisted of 18 content brands across 9 device platforms, requiring the release of 162 binaries to implement or update an SDK.
Client app crashes were being caused by 3rd party SDKs.
| Hypothesis
If we define a single data dictionary that encompasses all use cases, captures the events once in the platform, transforms them for multiple applications, and delivers events server to server, we will have better, cheaper, and safer data.
| Architecture
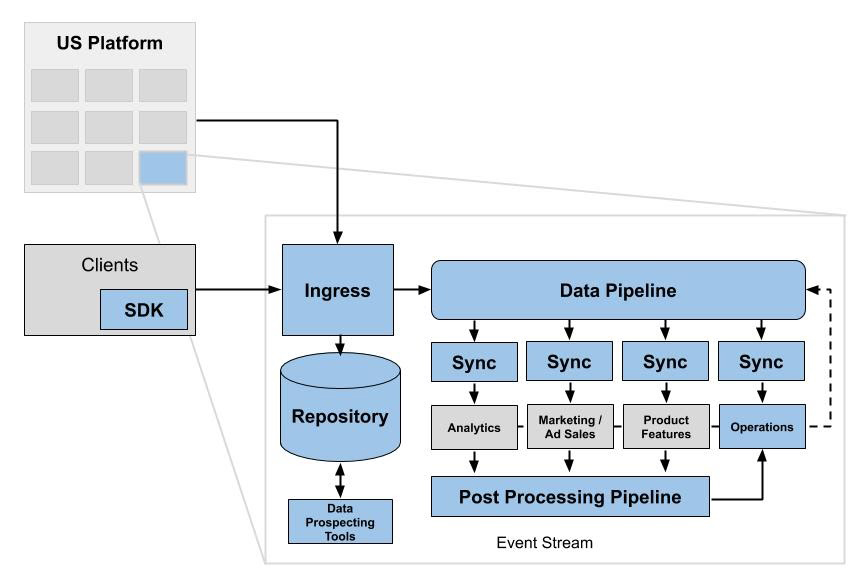
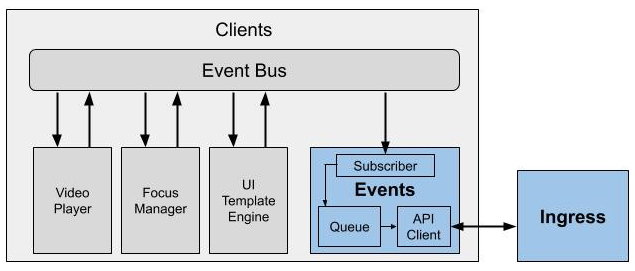
Event Stream was developed to capture data, form the events into topic and sub-topic streams and transform the data streams for subscriber systems. It consisted of 6 components: Events SDK, Ingress, Data Pipeline, Syncs, Post Processing Pipeline, and Storage Repository.
Ingress interfaces received event streams from clients and APIs. All events were published to the Data Pipeline and written to a Repository. Syncs used platform APIs to decorate data from the pipeline, then transform it to meet each subscriber’s specifications. The subscribers posted events back to the pipeline for other subscribers and storage. The Post Processing Pipeline confirmed the successful receipt of data by subscriber systems.
| Software Design
The new data capture and transform capabilities were delivered by a New York City platform engineering team for the US digital business in September 2018.
The software design had 7 entities in a single sequence to enable all required use cases.
Kinesis Firehose ingested the events and wrote the events to an S3 bucket and IoT MQTT simultaneously. Based on the event type the data was added to topics and sub-topics streams in the Data Pipeline.
Syncs were developed to enrich data from Data Pipeline topics with platform API data to meet subscriber system requirements. Syncs retried sending data using exponential backoff if the subscriber failed to respond or errored. The Post Processing Pipeline continuously queried all the subscribers, gathering data to verify that each of those systems made the data available in compliance with specifications. Errors were communicated to DevOps staff in near real-time.
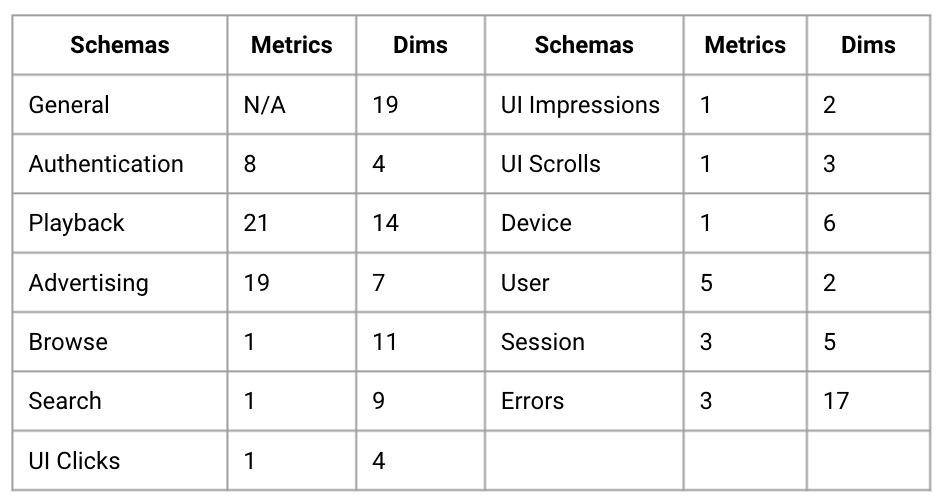
A critical component of the solution design was the data dictionary for capture. The first-party data dictionary defined 65 metrics with a total of 103 dimensions (i.e. dims) across 13 schemas. Each Sync employed a source to target schema that mapped the data dictionary to each subscriber system’s specification.
| Technologies
Time to market was reduced by using native AWS functions, like Kinesis, IoT, SQS, and S3.
Proprietary business and orchestration logic was developed with Golang to run in Lambdas.
InfluxDB with Kapacitor subscribed to the Data Pipeline to power Slack Alerts, PagerDuty, and Grafana dashboards for DevOps (e.g., ad beacons debugging and monitoring).
SQS-based syncs created event streams for feature APIs (e.g., Playhead markers API for cross-device viewing).
SQS-based Syncs supported Google Analytics, Adobe Analytics, Adobe Audience Manager, FreeWheel, Kochava marketing attribution, Braze and BlueShift CRM, Vidora content recommendations, comScore, and A/B testing.
A proxy captured events between publishers and Ingress API, writing them to MySQL to automate testing. Anomalies against the data schema were visualized using Tableau.
| Retrospective
◦ SQS fees will be the most costly portion of the solution. Replacing this messaging queue technology with an open source option will need to be road mapped to reduce AWS costs as traffic scales.
◦ Defining the data dictionary, source to target mappings, and user acceptance testing were each a higher level of effort than the actual coding. Optimizing these activities will speed time to market.
| Key Results
Fast Integrations
◦ Data integrations reduced from 54 resource weeks to 2
Increased Data Integrity
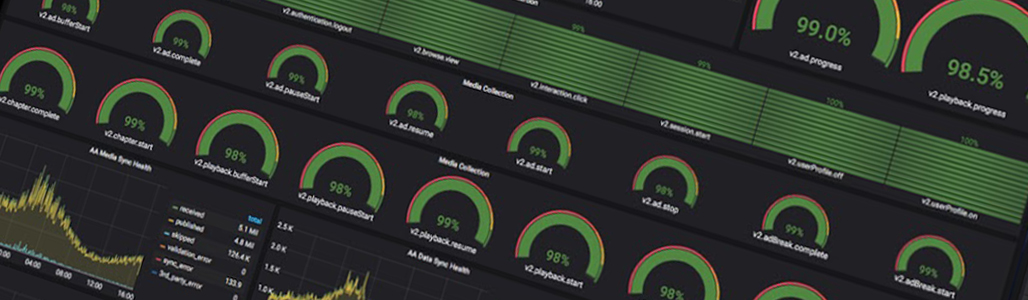
◦ Post Processing Pipeline verified less than 1% data loss in QA and production
Happier Customers
◦ 22% reduction in app crashes by removing SDK’s
Team Recognition
◦ Invited to AWS Reinvent and Adobe Summit in 2019 to present this technology